Introducing graphene-ng: running arbitrary payloads in SGX enclaves
A few months ago, during my keynote at Black Hat Europe, I was discussing how we should be limiting the amount of trust when building computer systems. Recently, a new technology from Intel has been gaining popularity among both developers and researchers, a technology which promises a big step towards such trust-minimizing systems. I’m talking about Intel SGX, of course.
Intel SGX caught my attention for the first time about 5 years ago, a little while before Intel has officially added information about it to the official Software Developer’s Manual. I’ve written two posts about my thoughts on this (then-upcoming) technology, which were a superposition of both positive and negative feelings.
Over the last 2 years or so, together with my team at ITL, we’ve been investigating this fascinating technology a bit closer. Today I’d like to share some introductory information on this interesting project we’ve been working on together with our friends at Golem for several months now.
Enclave-based computing
Recently the term “enclave-based” computing has been used increasingly often to describe a form of security container which allows for computations which are protected from the host, such as the external operating system, hypervisor, or even interference from the low-level firmware such as the BIOS/SMM/UEFI.
This is, naturally, in stark contrast to the usual definition of a security container as used today (and as implemented by VMs of various sorts, Linux/Docker containers, etc), which implies protection of the host from whatever code runs inside the container. In other words: the enclaves and the containers represent two different, complementary goals, and it is normally envisioned that both will be deployed at the same time.
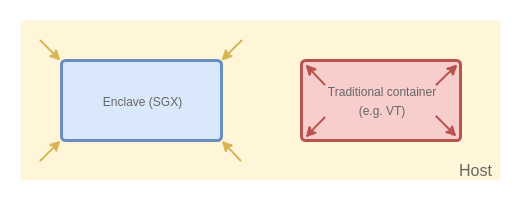
It’s not a surprise that people have been thinking about how to protect code and data running on a potentially compromised host for quite some time.
Even I wrote a piece back in 2011, where I discussed how we could attempt to somehow implement trusted execution within an untrusted cloud, utilizing Intel TXT technology (which could be thought of as a logical predecessor of Intel SGX). There has also been very interesting work done by Private Core (now Facebook), starting around 2012 and going on for a few years, unfortunately never released to the public (?). But solutions based on Intel TXT have been clumsy and vulnerable to some fundamental problems, such as e.g. SMM attacks.
Today Intel SGX seems like a very promising candidate (and so far the only one?) offering a reasonably good solution for enclave-based computing.
But Intel is not the only one, there are also other technologies with AMD Secure Encrypted Virtualization (SEV) being another interesting technology. Unfortunately, AMD SEV, while very promising at first sight, does have serious security weaknesses, such as the lack of integrity protection for 2nd-level page tables, and generally is believed to not to offer protection against malicious hypervisors, but rather only against accidental hypervisor vulnerabilities. Hopefully in the future AMD will improve the design and implementation of SEV.
There are also attempts to create so called Trusted Execution Environments (TEEs) on ARM-based systems, typically using the Trust Zone technology, which might resemble the idea of enclave-based computing, in that the payloads are to be protected from the main host OS. These, however, seem quite different to me, architecture-wise, because in case of Trust Zone we really are talking about a classic Security through Isolation Model, just with the hypervisor moved a level down the stack. From the user- and developer- point of view, the similarity might be more striking though. Not being an expert on ARM systems, there is also a possibility I’m missing some crucial innovation here, which makes these solutions also more similar to Intel SGX and AMD SEV.
Intel SGX is a hardware extension, meaning one needs to have a reasonably modern Intel processor in order to be able to use it. Typically this should not be a problem for most modern laptops which are based on most of the recent Intel processors.
But having an SGX-ready hardware is just half of the story, as one also needs specially-designed software to make use of SGX-provided features. And Intel does offer an SDK exactly for this purpose.
So, how does one port an application to be usable within an SGX enclave? As it turns out, that is not an easy task…
Intel SGX challenges and problems
It is not an easy task to port an application to run within an SGX container, because Intel has envisioned SGX as a protection technology for only small parts of the application code and data. Prime example includes protection of only the crypto code (key generation, sign and decrypt operations), while leaving the whole rest of the application wide open to the attacks from the host OS.
This kind of thinking is not entirely new in the industry, where vendors consider the protection of the keys (which usually belong to the vendors, such as e.g. the signing keys for bank transactions or decryption keys for DRM-protected material) to be of primary concern, while putting less emphasis on protection of the actual user data (e.g. the content of the user’s email).
There are more problems with SGX, however.
First, Intel SGX has its own Remote Attestation scheme, which oddly, requires an Intel-operated server, so called Intel Attestation Service (IAS), to be used to verify the proof of attestation. This proof of attestation is called: “quote” and it is the same name as used in “classic” TPM-based Remote Attestation, although the SGX “quote” is a bit different. The Intel’s decision to encrypt it (not just sign), effectively limiting its verification only to Intel-operated servers seems questionable at best. Not only does it introduce a single point of failure to any infrastructure based on SGX, but also gives Intel a possibility to stealthy spoof attestation results for select users, this way facilitating selective plausibly deniable backdooring (note that Intel can always build in a backdoor, just that a generic backdoor within the silicon is hard to be used selectively, and surely is not plausibly deniable).
Another issue with SGX is the requirement for any SGX enclave to be signed with Intel-blessed vendor’s signing key. In other words, it is not possible to load an SGX enclave (other than in debug mode) without entering into a legal contract with Intel. The rationale behind this is believed to be to prevent blackbox malware within enclaves, something I (theoretically) described in the early days of SGX…
(BTW, in the SDM manual, Intel describes a special MSR resister which could be used to provide a hash of a custom, so called, Launch Enclave, seemingly making it possible to get around this requirement to have enclaves signed only by Intel-blessed keys. Unfortunately, it is strongly believed that when one decides to use a custom Launch Enclave, then the Remote Attestation would no longer work, yielding the whole technology mostly useless…)
There are also some implementation-level problems with SGX, which should be mentioned here for completeness. One is the rather small limit for the amount of protected memory accessible for all the enclaves in the system, which is called the Enclave Page Cache, or EPC. On today’s system this amounts to only 128 MB currently. Luckily, the Intel-provided driver (which is part of the SGX SDK) performs on-the-fly paging of enclave memory. This paging goes to the DRAM, not to disk, so while there is some performance penalty imposed by this operation, it is not terrible (in our experiments, for payloads which utilize memory in a more-or-less linear fashion, this amounts to less than 30% overhead). Of course the driver (or the host kernel) only sees the encrypted and integrity-protected pages, so cannot steal, nor meaningfully rearrange them.
Finally, one last problem, which however cannot be dismissed lightly, is the existence of various side-channel attacks, which can leak secrets out of the enclave’s code to the host OS. It is especially challenging to neutralize such side channels, given the fact that the attacker can control the whole host OS. No doubt Intel and other researchers will continue to research this area and likely implement an increasing number of protections against such attacks (most likely on the level of SDK/compiler?).
Running whole applications in SGX enclaves
Despite all the problems with SGX discussed above, I still believe this is a technology with a great potential, and that most of the problems could be solved, or at least improved upon significantly. But to make it truly useful, especially for users, not just vendors, we really need to find generic ways of how to run whole, unmodified applications within SGX enclaves. Pretty much like if they were “VMs” of some kind.
There are two key challenges with achieving this goal, however:
-
First we need to expose a near-complete API such as POSIX or Win32 (or Linux or Windows syscall API), so that the process running in the enclave could behave as if it ran natively under the host OS. The challenge here is that, naturally, we cannot simply pass through down to the host, because… the host is untrusted in our threat model.
-
The other challenge is how to meaningfully bind the application inside the enclave to some secret, which could later be used to construct a proof that the application does indeed execute inside a valid SGX enclave. Here we would like to prevent the most obvious attack against enclave-based computing which works by having the attacker… only simulating that the process runs within an enclave, but in reality the execution takes place in normal execution mode (e.g. in case of Intel SGX, the attacker would skip the EINIT/EENTER instructions).
As for solving the first challenge, a few papers and projects have already been presented: Microsoft Haven, SCONE, Graphene SGX, and Panoply.
From the security point of view, the primary difference between these projects, is how they implement the rich OS-like API, which is to be exposed to the application within the enclave.
On the one end of the spectrum are projects which take the “minimal TCB size” approach, which means they try to pass-through as much API call logic to the underlying host OS as possible, while performing some sanity checks on the results returned from the host OS. This approach has been taken by Scone and Panoply, and their rationale is that minimizing the amount of code within an SGX enclave (i.e. the size of TCB), should be the primary goal.
![]()
The alternative approach, embraced by Haven and Graphene, has been to “minimize the untrusted interface” to the host OS. The rationale here is that it is the size of the attack surface that matters more, than the amount of code inside the enclave.
I personally agree with the latter approach, because I believe that the size and complexity of the external interface is more critical. After all if there is no way for the attacker to reach the code inside (e.g. pass arbitrary parameters to functions), then it is not so problematic that there might be bugs in this code. By keeping the external interface small and simple, we can assure that with a reasonable degree of assurance in practice. For this reason we have built our solution, discussed below, on top of Graphene.
The second challenge is often neglected, as authors (especially of academic papers) tend to focus more on the first problem, often leaving proof of execution within SGX enclave as “future work” (the MS Haven paper being a notable exception here). Arguably, however, this is the most crucial aspect of any enclave-based solution, as otherwise, no matter how secure the execution environment, the attacker would always be able to essentially ruin the whole scheme by using an emulation attack in which the actual payload will get executed outside of the enclave (or within a real enclave, just such that is controlled by the attacker).
One “little detail” that should also be taken into account is how does the application inside the enclave generate random numbers. Over decades operating systems and applications have come up with various, often surprising ways to generate randomness from different sources of entropy, such as e.g. interrupts, mouse, disk or networking use patterns, etc. When running within an enclave, we should keep in mind that all such “external” events (and only external events can bring entropy, right?) can be fully controlled (at last monitored) by the host OS. This means the host OS can always learn any key the application would generate inside the enclave, which in turn yields any Remote Attestation scheme meaningless. Fortunately, there is a solution to this problem: a hardware instruction for generating randomness: RDRAND. But if the application, for whatever reason, does not use RDRAND (or a proper OS-service, which we intercept in the libOS), but instead tries to employ some Do-It-Yourself method, then we might have a serious problem.
Graphene, graphene-ng and Golem
Together with Golem, we have been working on a solution to the problem of running arbitrary payloads (more specifically: Docker Linux-based containers) for several months now, and I’d like to share a bit of a status of where we are right now, and where we would like to get.
Golem is building a decentralized compute cloud (think EC2 married with SETI@home) and enclave-based computing offers a potential to solve two critical problems any such decentralized network faces: 1) how to ensure users who contribute compute power do indeed execute payloads for which they are being paid, and 2) to offer confidentiality to payloads, so that the owners of the computer performing the computations could not eavesdrop on the data being processed.
We (ITL) on the other hand, are also very interested in enclave-based computing, with one natural application being for use in future versions of Qubes OS.
As mentioned above, we have chosen to base our solution on Graphene SGX, because its architecture seemed the most appealing to us, as explained in the previous section.
Unfortunately, what has looked good on architecture-level (or, to say more directly: on paper), turned out to be much less usable in practice. Any more complex payloads we tried to run under Graphene, such as Blender renderer processing any more complex scenes, revealed dozens of bugs within the Graphene LibOS implementation (mostly race conditions). Luckily these were not security-relevant bugs within our threat model, because in this context we assume the attacks are coming from the host, and not from the payload (and a malicious payload can always be… malicious to itself and its own data, nothing can be done about that).
Golem also considers attacks coming from potentially malicious payloads attacking the host. To prevent them they use a different sandboxing technology, which does not rely on Graphene. This is an important detail to stress, because Graphene actually does advertise itself as a framework to also sandbox the payloads. Our quick analysis of the code revealed, however, that this extra functionality does not work well and could be circumvented relatively easily.
Another problem with the original Graphene project is no meaningful support for proving to the remote party (i.e. the user) that the payload has executed indeed in a proper enclave, properly-protected (the second challenge discussed above).
We’ve spent months finding and fixing the bugs within Graphene and also designing and implementing support for ensuring the remote party the execution and processing of their data has indeed been done within a properly protected enclave.
Our solution for this latter challenge has been designed for batch-processing-like payloads, which take some files on input, perform calculations (e.g. render part of the scene) and then create some output when done. In the future it could be extended to cover more interactive payloads as well. The user is offered a tool, which is responsible for automatically verifying Remote Attestation proof, and encrypting the input file(s) using a public key generated by our framework running within the enclave. This way the user gains assurance that her data could be decrypted only by 1) a payload with specific measurement (hash of the code or hash of the developer’s signing key), 2) running within a proper SGX enclave, 3) on proper, e.g. non-buggy hardware, 4) with the proper set of properties (e.g. not in SGX debug mode).
Given the amount of modifications we have introduced to Graphene, and also because our needs to be able to progress with development significantly faster than the original Graphene project has been doing recently, we’ve decided to fork the project. We will be making the repository public in the coming weeks, most likely after the summer holidays, together with a technical paper describing the challenges I’ve quickly tried to summarize above. For today we just would like to show off a short demo movie below :)
We would also like to thank the original Graphene maintainers and all the contributors for starting this exciting project!
Demo time!
Without further ado, let’s take a look at the demo :)

In the demo above several steps are presented (they are to be done only by the application vendors, not by users of the payloads):
-
First we’re building the base Docker container which contains the necessary Graphene-based infrastructure:
golem-sgx-template -
Then we’re creating a Dockerfile for an exemplary application container, in this case for running Blender inside an SGX enclave (
golem-sgx-blender):
# Inherit from Golem SGX based template:
FROM golem-sgx-template:latest
# Install Blender:
# We don't use Ubuntu repo, because it contains some older Blender version.
# The /wget_and_check.sh is a simple script exposed by the golem-sgx-template Docker
# which verifies integrity of the downloaded components.
RUN mkdir /blender/
RUN /wget_and_check.sh \
"https://ftp.halifax.rwth-aachen.de/blender/release/Blender2.79/blender-2.79b-linux-glibc219-x86_64.tar.bz2" \
"/tmp/blender.tar.bz2" \
"43824a4e0b0c6de6fa34ff224eec44c1cc9f26a95f6f3c8c2558d1c05704183c"
RUN tar xjf /tmp/blender.tar.bz2 --strip-components=1 -C /blender/
# (Automatically) create the manifest for the payload:
WORKDIR /blender/
COPY blender.manifest.template .
RUN /prepare_manifest.sh /blender/blender
# Run the payload under Graphene:
CMD ["/graphene_sgx_run.sh", "blender", \
"-t", "1", \
"-b", "/input/input.blend", \
"-P", "/input/change_params.py", \
"--", "1920", "1080", "4", "50", "/output/out.png"]
As we can see the Dockerfile inherits from the golem-sgx-template, and then
it’s a pretty standard Dockerfile, except for two things: 1) we need to run a
special script to create a so-called manifest for the payload (more on this
below), and 2) start the actual payload using the wrapper script
(/graphene_sgx_run.sh, also included in the base Docker template), which takes
care of running the given executable under Graphene, ensuring specific
options are turned on (such as telling it to use SGX-capable PAL).
The payload manifest mentioned above is a crucial thing: it contains a list of all the files which should be made available to the payload running within the SGX enclave. This includes the input and output files, which are automatically encrypted and integrity-protected by a corresponding user-side tool, in such a way that only the proper payload in a valid SGX enclave can read and write them. For Golem applications this process is going to be fully automatic (as seen above), but for other cases the container vendor might need to tweak this manifest by defining different lists of input and output files. The other files, such as the list of all the libraries and other dependencies is generated automatically and this should work for all the cases. More details in the upcoming paper.
- Now we’re ready to build and sign the final Docker image. Now the Docker imaging hosting a given payload (in this case a Blender renderer) is finalized (sealed via digital signature made above) and ready for users to run it.
Having such a final docker image, anyone can now run it (e.g. a compute node of the Golem network) with a simple wrapper script, e.g.:
./../docker_run_with_sgx.sh -v "`pwd`/sample_input:/input" -v "`pwd`/render_output:/output" golem-sgx-blender-signed
Future plans and wishes
So, what are our plans and expectations for Intel SGX in the longer term?
First and foremost we look forward to Intel doing the “SGX liberation”, as I like to call it. This liberation should comprise two, independent aspects:
-
Liberating Remote Attestation, which means Intel should allow anyone, not just its own IAS servers to perform Quote verifications (of course, it’s perfectly fine, and probably justified if Intel will continue to operate and offer IAS to those customers who find such a service convenient),
-
Allowing to load enclaves signed with any key, not just one “blessed” by Intel. But at the same time still allowing for meaningful Remote Attestation to work. By meaningful attestation I understand one that performs signing of the Quote using keys derived from the processor’s private key, of course.
Other aspects that we believe are crucial in further adoption of SGX technology are:
-
Allowing for a secure communication path between an enclave and a GPU. This is important for both Golem-like applications, where the payload might want to utilize GPU for computations, as well as for client-like applications, where we would like some user applications, such as e.g. a messaging app or email client, to be able to safely display decrypted content to the user, without the fear of the (untrusted) host OS seeing and capturing it.
-
Additionally allowing for secure communication with mouse and keyboard (or generally HID devices), to facilitate safe use in client applications, such as just mentioned messaging, email, banking and wallet-like applications.
-
Increase the amount of EPC to facilitate running big, complex payloads within enclave with minimal performance impact.