Partitioning my digital life into security domains
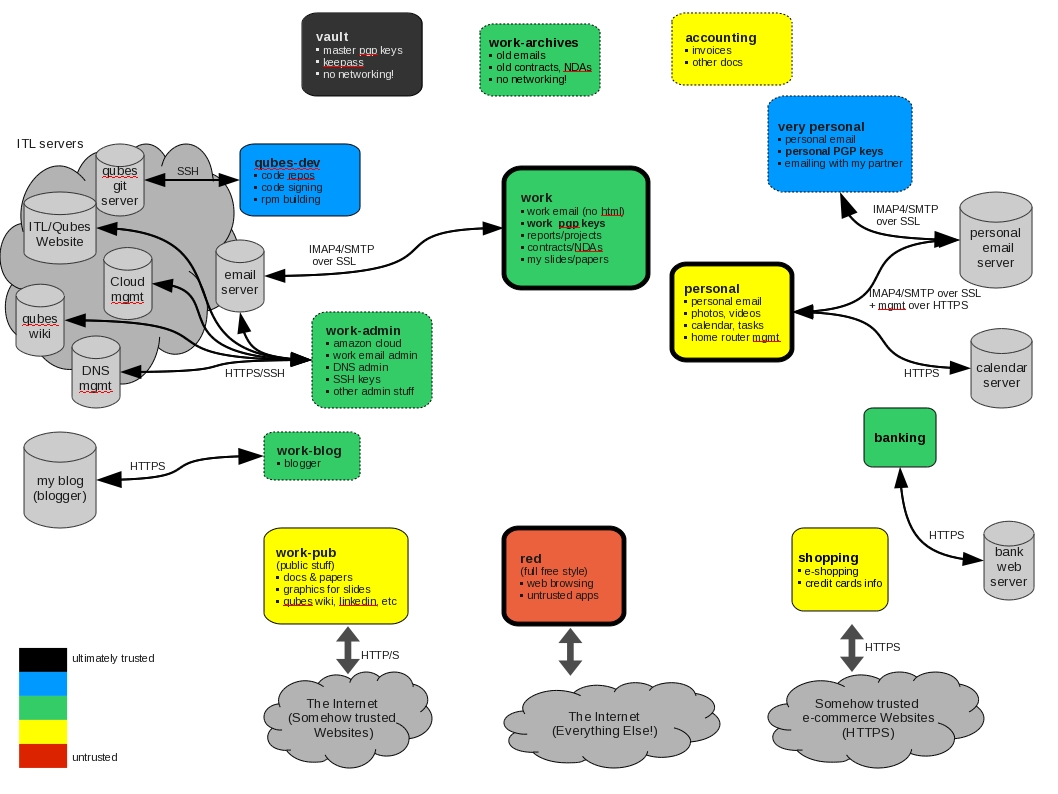
Let's discuss this diagram bit by bit. The three basic domains are work (the green label), personal (the yellow label), and red (for doing all the untrusted, insensitive things) – these are marked on the diagram with bold frames.
A quick digression on domain labels (colors) – in Qubes OS each domain, apart form having a distinct name, is also assigned a label, which basically is one of the several per-defined colors. These colors, which are used for drawing window decorations by the trusted Window Manager (color frames), are supposed to be user friendly, easy noticeable, indicators of how trusted a given window is. It's totally up to the user how he or she interprets these colors. For me, it has been somehow obvious to associate the red color with something that is untrusted and dangerous (the “red light” -- stop! danger!), green with something that is safe and trusted, while yellow and orange with something in the middle. I have also extended this scheme, to also include blue, and black, which I interpret as indicating progressively more trusted domains than green, with black being something ultimately trusted.
Back to my domains: the work domain is where I have access to my work email, where I keep my work PGP keys, where I prepare reports, slides, papers, etc. I also keep various contracts and NDAs here (yes, these are PDFs, but received from trusted parties via encrypted and signed email – otherwise I open them in Disposable VMs). The work domain has only network access to my work email server (SMTP/IMAP4 over SSL), and nothing more.
For other work-related tasks that require some Web access, such as editing Qubes Wiki, or accepting LinkedIn invites, or downloading cool pictures from fotolia.com for my presentations, or specs and manuals from intel.com, for all this I use work-pub domain, which I have assigned the yellow label, meaning I consider it only somehow trusted, and I would certainly never put my PGP keys there, or any work-related confidential information.
The personal domain is where all my non-work related stuff, such as personal email and calendar, holiday photos, videos, etc, are held. It doesn't really have access to the Web, but if I was into social networking I would then probably allow HTTPS to something like Facebook.
Being somehow on the paranoid side, I also have a special very-personal domain, which I use for the communication with my partner when I'm away from home. We use PGP, of course, and I have a separate PGP keys for this purpose. While we don't discuss any secret and sensitive stuff there, we still prefer to keep our intimate conversations private.
I use shopping for accessing all the internet e-commerce sites. Basically what defines this domain is access to my credit card numbers and my personal address (for shipping). Because I don't really have a dedicated “corporate” credit card, I do all the shopping in this domain, from groceries, through sports equipment, on hotel/plane reservations ending. If I had separate business credit cards, then I would probably split my shopping domain into personal-shopping and work-shopping. I also have banking domain, which I use only for managing my bank account (which again combines both my personal and company accounts).
I also have a few specialized work-related domains, that I rarely use. The work-admin domain is used to manage almost all of the ITL servers, such as our webserver, Qubes repo & wiki servers, email server and DNS management, etc. This domain is allowed only SSH traffic to those server, and HTTPS to a few Web-based management servers. The work-blog is used to manage this very blog you're reading now. The reason why it is separate from work-admin or work, is because I'm over paranoid, and because I fear that if somebody compromises the blogger service, and subsequently exploits a bug in my browser that I use for editing my blog, than I don't want this person to be able to also get admin access to all the ITL servers.
Similarly, if somebody somehow compromised e.g. the Amazon Web Management Console, and then exploited my browser in work-admin, then I would like at least to retain access to my blog. If I used twitter, I would probably also manage it from this work-blog domain, unless it was a personal twitter account, in which case I would run it from personal.
The qubes-dev domain is used for all the Qubes development, merging other developers' branches (after I verify signatures on their tags, of course!), building RPMs/ISOs (yes, Qubes Beta 1 will ship as a DVD ISO!), and finally signing them. Because the signing keys are there, this domain is very sensitive. This domain is allowed only SSH network access to our Qubes git server. Again, even if somebody compromised this Git server, it still would not be a big problem for us, because we sign and verify all the tags in each others repos (unless somebody could also modify the SSH/Git daemons running there so that they subsequently exploit a hypothetical bug in my git client software when I connect to the server).
I also decided to keep all the accounting-related stuff in a separate domain – whenever I get an invoice I copy it to the accounting domain. The rationale for this is that I trust those PDFs much less than I trust the PDFs I keep in my work domain.
Once a year I move the old stuff from my work domain, such as old email spools, old contracts and NDAs, to the work-archives domain. This is to minimize the potential impact of the potential attack on my work domain (my work domain could be attacked e.g. by exploiting a hypothetical bug in Thunderbird's protocol handshake using a MITM attack, or a hypothetical bug in GPG).
The vault domain is an ultimately trusted one where I generate and keep all my passwords (using keepass) and master GPG keys. Of course, this vault domain has no networking access. Most of those passwords, such as the email server access password is also kept in the specific domains which uses them, such as the work domain, and more specifically in the Thunderbird client (there is absolutely no point in not allowing e.g. Thunderbird to remember the password – if it got compromised it would just steal it the next time I manually enter it)
And finally, there is the previously mentioned red domain (I have tried to call it junk or random in the past, but I think red is still a better name after all). The red domain is totally untrusted – if it gets compromised, I don't care – I would just recreate it within seconds. I don't even back it up! Basically I do there everything that doesn't fit into other domains, and which doesn't require me to provide any sensitive information. I don't differentiate between work-related and personal-related surfing even – I don't care about anonymity for all those tasks I do there. If I was concerned about anonymity, I would create a separate anonymous domain, and proxy all the traffic through a tor proxy from there.
Now, this all looks nice and easy ;) but there is one thing that complicates the above picture...
Data flows between the domains
The diagram below shows the same domains, but additionally with arrows symbolizing typical data flows between them.
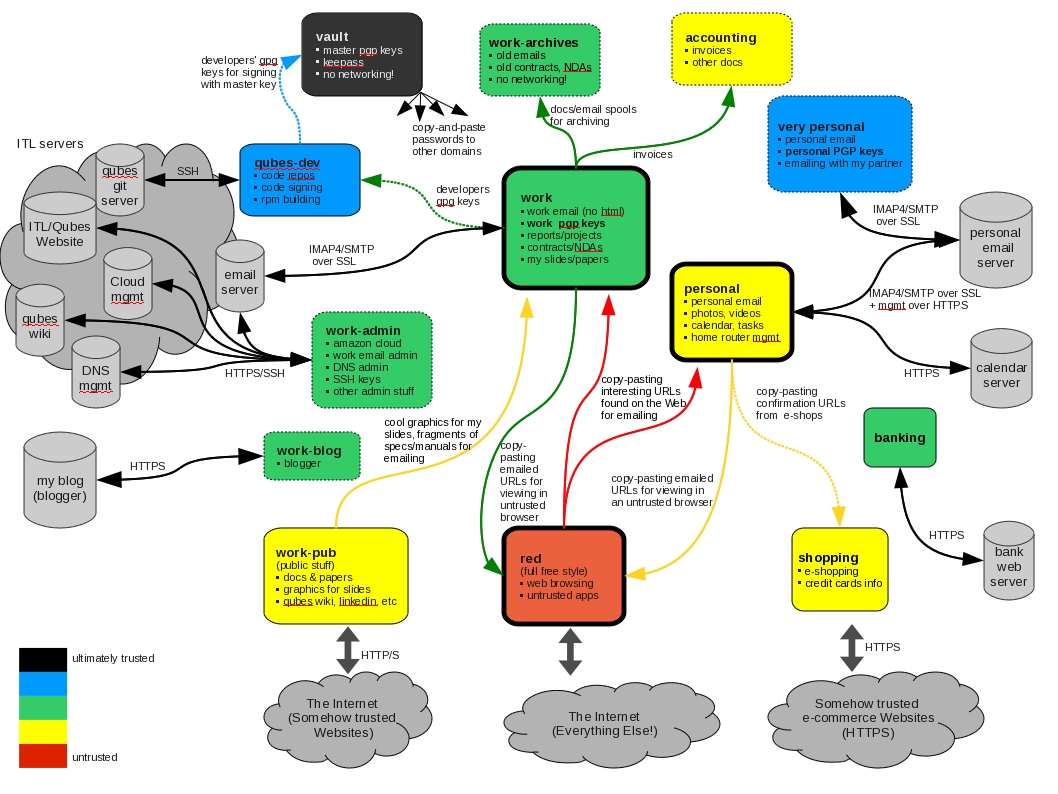
You can see that most of the usual data flows are from more trusted domains to less trusted domains – e.g. copy and pasting a URL that I receive via email in my work domain, so that I could open it in my untrusted browser in red, or moving invoices from my work domain (where I receive them via email) to the accounting domain.
But there are, unfortunately, also some transfers from less trusted domains to more trusted ones. One example is copy and pasting an interesting URL that I just stumbled upon when surfing in the red domain, and that I would like to share with a college at work, or a friend, and so I need to copy and paste it to my email client in either work (colleague) or personal (friend) domain.
Now, copying data from less trusted domains to more trusted ones presents a significant problem. While one could think that pasting an URL into Thunderbird email editor is a pretty harmless operation, it's still is an untrusted input – and we don't really know what the red domain really pasted into its local clipboard, and so what we will paste into the work domain's Thunderbird email editor (perhaps 64kB of some junk that will overflow some undo buffer in the editor?). And even more scary is the example with copying the cool-looking graphics file from the Web into my work domain so that I could use it in my presentation slides (e.g. an xkcd . Attacks originating through malicious JPEGs or other graphics format, and exploiting bugs in rendering code have been known for more than a decade.
But this problem – how to handle data flows from less trusted systems to more trusted ones – is not easily solvable in practice, unfortunately...
Some people who design and build high-security systems for use by military and government takes a somehow opposite approach – they say they are not concerned about less-trusted-to-more-trusted data transfers as long as they could assure there is no way to perform a transfer in the opposite direction.
So, if we could build a system that guarantees that a more trusted domain can never transfer data to a less trusted domain (even if both of those domains are compromised!), then they are happy to allow one-way “up transfers”. In practice this means we need to eliminate all the covert channels between two cooperating domains. The word cooperating is a key word here, and which makes this whole idea not practical at all, IMHO.
So, if we could build a system that guarantees that a more trusted domain can never transfer data to a less trusted domain (even if both of those domains are compromised!), then they are happy to allow one-way “up transfers”. In practice this means we need to eliminate all the covert channels between two cooperating domains. The word cooperating is a key word here, and which makes this whole idea not practical at all, IMHO.
Elimination of the covert channels between cooperating domains is indeed required in this scheme, because the assumption is that the data transfer from the less trusted domain could have indeed compromised the more trusted domain. But this, at least, should not result in any data leak back to the originating domain, and later to the less-classified network, which this less-trusted domain is presumably connected to. One of the assumptions here is that the user of such a system is connected to more than one, isolated networks. Even in that case, elimination of all the covert channels between domains (or at least minimizing their bandwith to something unusable – what is unusable, really?) is a big challenge, and can probably only could be done when we're ready to significantly sacrifice the system's performance (smart scheduling tricks are needed to minimize temporal covert channels).
I would like to make it clear that we are not interested in eliminating cooperative covert channels between domains in Qubes any time in the near future, and perhaps in the long term as well. I just don't believe into such approach, and I also don't like that this approach does nothing to preserve the integrity of the more-trusted domain – it only focuses on the isolation aspect. So, perhaps the attacker might not be able to leak secrets back to the less trusted domain, but he or she can do everything else in this more trusted domain. What good is isolation, if we don't maintain integrity?
An alternative solution to handling the less-trusted-to-more-trusted data transfers, is to have trusted “converters” or “verifiers” that could handle specific file types, such as JPEGs, and ensure we get a non-malicious file in the destination domain. While this might remind the bad-old A/V technology, it is something different. Here, the trusted converters would likely be some programs written in a safe language, running in another trusted domain, rather than a big ugly A/V with a huge database of signatures of “bad” patterns of what might appear in a JPEG file. The obvious problem with such an approach is that somebody must write those converters, and write them for all file types that we wish to allow to be transferred to more trusted domains. Perhaps doable in the longer-term, and perhaps we will do it in some future version of Qubes...
Right now we are ignoring this problem, and we say that all less-trusted-to-more-trusted transfers are to be done on the user's own risk :) You're welcome to submit trusted converters for your favorite file type(s) in the meantime!
Copying files between domains
Speaking of copying files between domains, there is another security catch here. If we imagined two physically separated machines that share no common network resources, the only way to move files between those two air-gaped machines would be via something like a USB stick or a CDROM or DVD disc. But inserting a USB drive or CDROM into a machine triggers a whole lot of actions: from parsing device-provided information, loading required drivers (for USB), parsing the driver's partition table, mounting and finally parsing the filesystem. Each of this stage requires the machine's OS to perform a lot of untrusted input processing, and the potential attack space here is quite large. So, even if we could limit ourselves to copy only harmless files between machines/domains (perhaps they were somehow verified by a trusted party in-between, as discussed above), still there is a huge opportunity that the originating domain could compromise the target domain.
In Qubes Alpha we have been using a similar file copy mechanism, using a virtual stick for file copy between domains. In Qubes Beta 1 we will provide a new scheme based on same shared memory channel that we use for GUI virtualization – the technical details of this solution will be available soon in our wiki. The most sensitive element in this new scheme is the un-cpio-like utility that runs in the target domain and unpacks the incoming blob into the pre-defined directory tree (e.g. /home/user/incoming/from-{domainname}/). We believe we can write pretty safe un-cpio-like utility, in contrast to secure all the previously mentioned elements (USB device parsing, partition parsing, fs parsing). The Qubes Beta 1 is planned to be released at the end of March, BTW.
Partitioning enforcement and easy of use
For any security partitioning scheme to make sense in real life, it is necessary to have some enforcement mechanism that would ensure that the user doesn't mistakenly bypass it. Specifically for this purpose we have come up with special, previously-mentioned firewalling support in Qubes Beta 1, that I will cover in a separate article soon.
Anther thing is to make the partitioning easy to use. For instance, I would like to be able to setup a hint in the policy, that when I click on an URL in an email I received in my work domain that it should be automatically opened in the red domain's default Web browser. Currently we don't do that in Qubes, but we're thinking about doing it in the near future.
Summary
Partitioning one's digital life into security domains is certainly not an easy process and requires some thinking. This process is also very user-specific. The partitioning scheme that I've come up for myself is quite sophisticated, and most people would probably want something much simpler. In case of corporate deployments, the scheme would be designed by CIO or IT admins, and enforced on users automatically. Much bigger problem are home and small business users, who would need to come up with the partitioning themselves. Perhaps in future versions of Qubes we will provide some ready to use templates for select "typical" groups of users.